Multiple regression generally explains the relationship between multiple independent or predictor variables and one dependent or criterion variable. A dependent variable is modeled as a function of several independent variables with corresponding coefficients, along with the constant term. Multiple regression requires two or more predictor variables.
\(\hat{Y}\) is the predicted or expected value of the dependent variable, and is always numeric and continuous.
\(b_0\) is the value of \(\hat{Y}\) when all of the independent variables \(x_1 -x_n\) are equal to zero,
\(x_1 -x_n\) are distinct independent or predictor variables
\(b_1 - b_n\) are the estimated regression coefficients. Each regression coefficient represents the change in \(\hat{Y}\) relative to a one unit change in the respective independent variable.
In the multiple regression situation, \(b_1\), for example, is the change in \(\hat{Y}\) relative to a one unit change in \(x_1\), holding all other independent variables constant (i.e., when the remaining independent variables are held at the same value or are fixed).
Assumptions
Independence: The Y-values are statistically independent of each other as well as the errors. As with simple linear regression, this assumption is violated if several Y observations are made on the same subject.
Linearity: The mean value of Y for each specific combination of values of the independent variables (\(X_1, X_2...X_n\)) is a linear function of the intercept and parameters (\(\beta_0, \beta_1,...\))
Homoscedasticity: The variance of Y is the same for any fixed combination of independent variables.
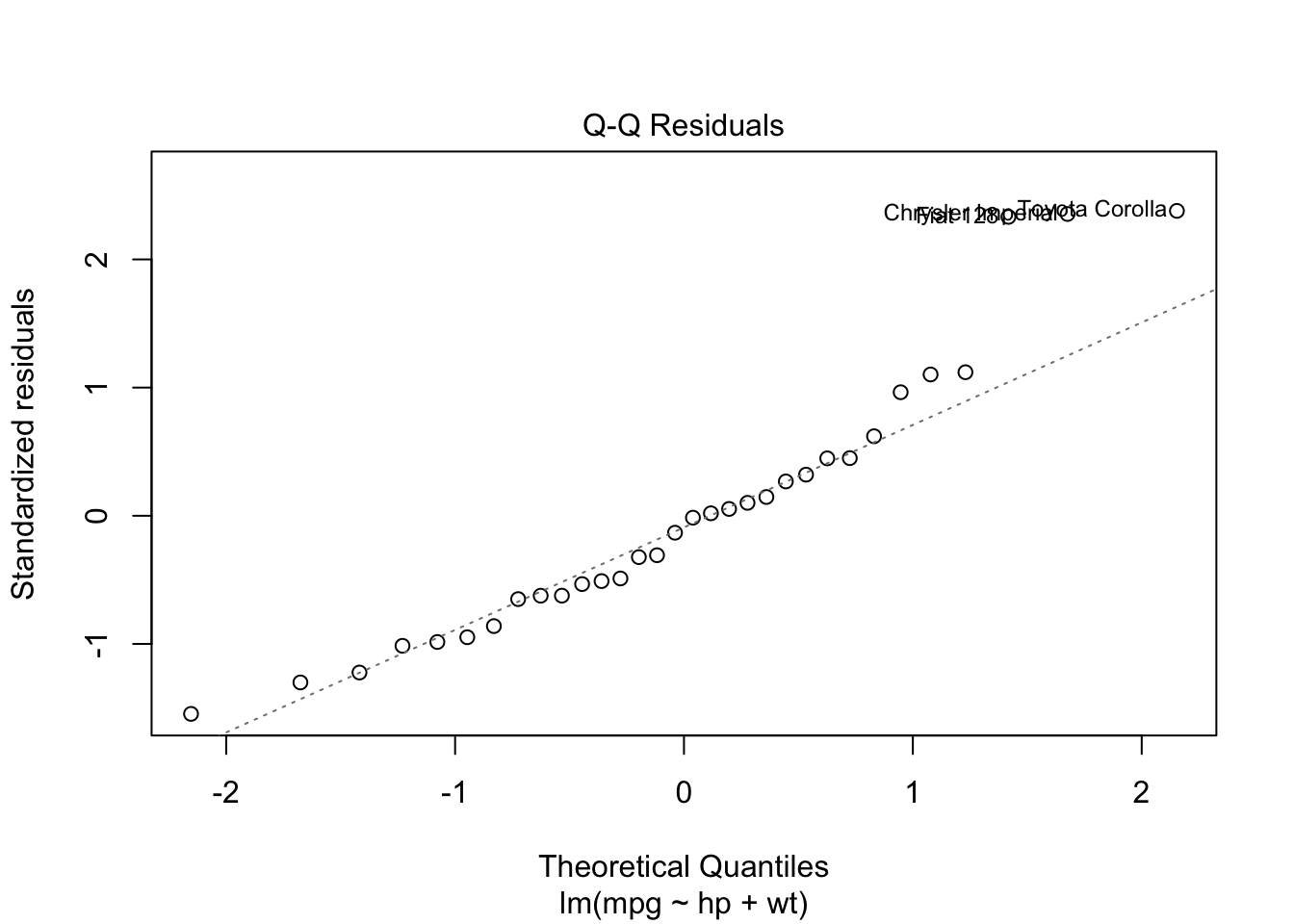
Normal Distribution: The residual values are normally distributed with mean zero.
Multicollinearity: Multicollinearity cannot exist among the predictors (the variables are not correlated)
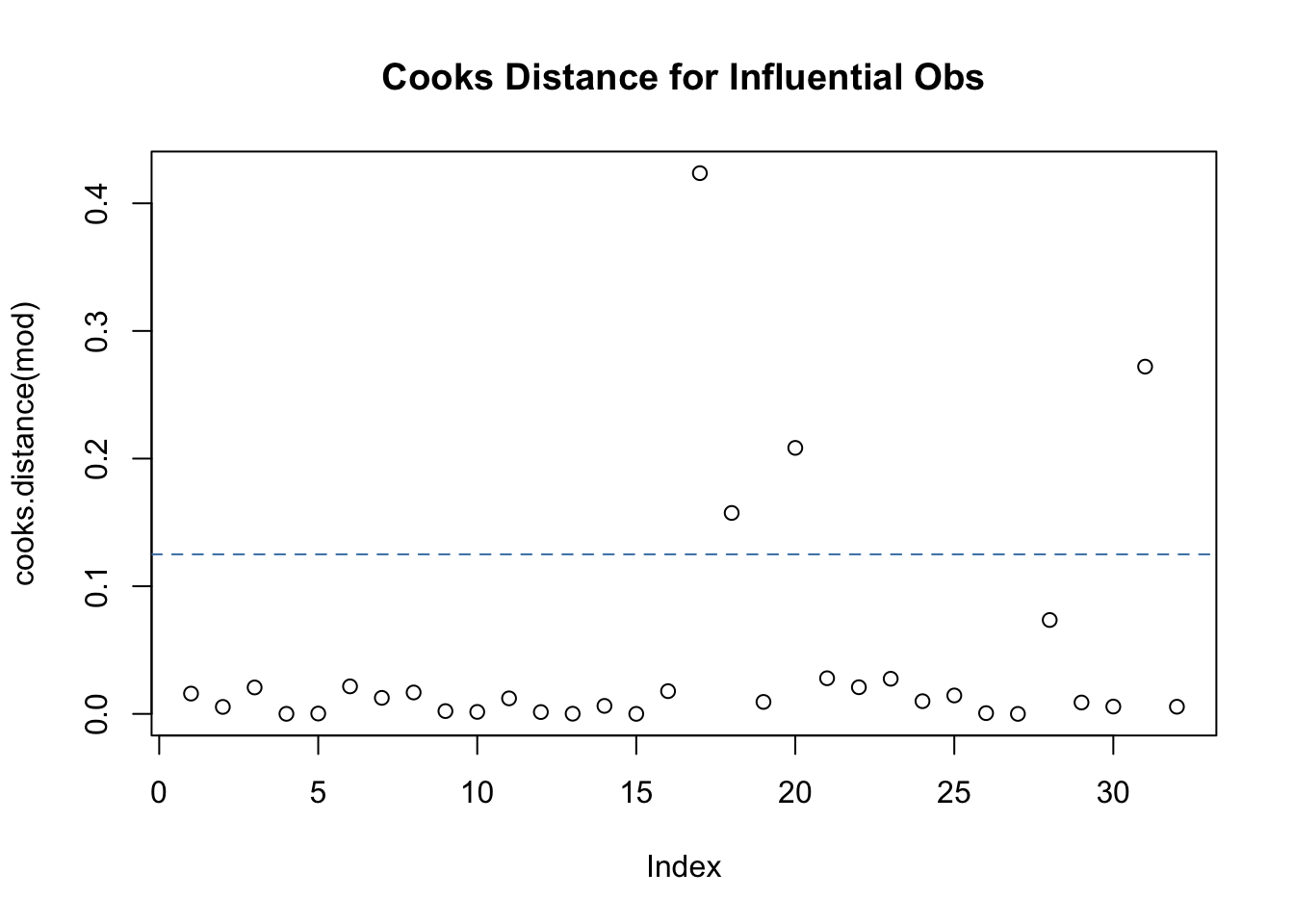
# cook's d -> are the outliers in the qq plot driving the relationship in the model? cooks.distance(mod)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive
1.589652e-02 5.464779e-03 2.070651e-02 4.724822e-05
Hornet Sportabout Valiant Duster 360 Merc 240D
2.736184e-04 2.155064e-02 1.255218e-02 1.677650e-02
Merc 230 Merc 280 Merc 280C Merc 450SE
2.188702e-03 1.554996e-03 1.215737e-02 1.423008e-03
Merc 450SL Merc 450SLC Cadillac Fleetwood Lincoln Continental
1.458960e-04 6.266049e-03 2.786686e-05 1.780910e-02
Chrysler Imperial Fiat 128 Honda Civic Toyota Corolla
4.236109e-01 1.574263e-01 9.371446e-03 2.083933e-01
Toyota Corona Dodge Challenger AMC Javelin Camaro Z28
2.791982e-02 2.087419e-02 2.751510e-02 9.943527e-03
Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa
1.443199e-02 5.920440e-04 5.674986e-06 7.353985e-02
Ford Pantera L Ferrari Dino Maserati Bora Volvo 142E
8.919701e-03 5.732672e-03 2.720397e-01 5.600804e-03
# Plot Cook's Distance with a horizontal line at 4/n to see which observations# exceed this thresdholdn<-nrow(mtcars)plot(cooks.distance(mod), main ="Cooks Distance for Influential Obs")abline(h =4/n, lty =2, col ="steelblue")
Cook’s distance refers to how far, on average, predicted y-values will move if the observation in question is dropped from the data set.
We can clearly see that four observation in the dataset exceed the 4/n threshold. Thus, we would identify these two observations as influential data points that have a negative impact on the regression model.
Since there are very few extreme values according to cook’s d values, we can assume they are not the driving force between the relationship of the predictor and outcome.
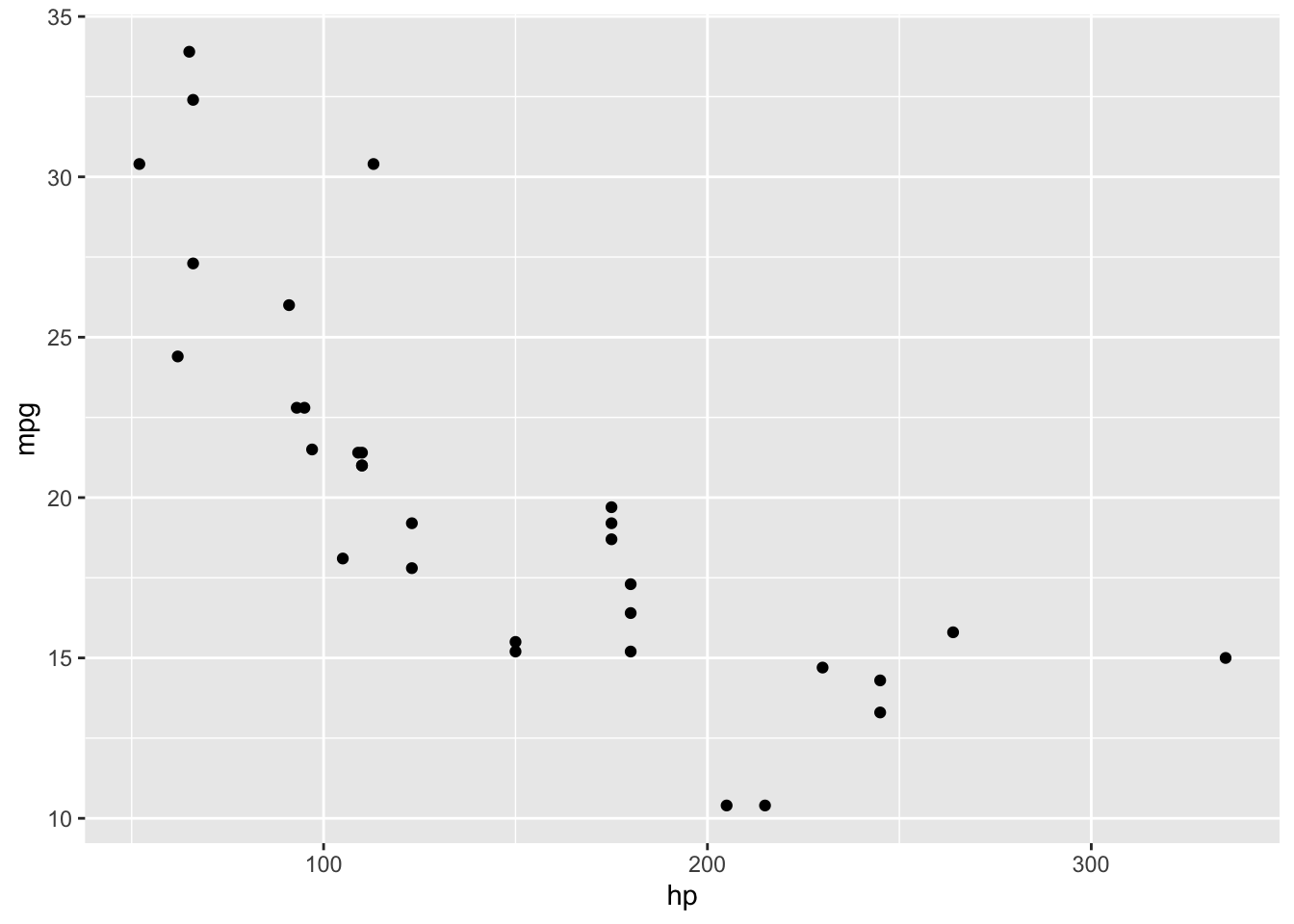
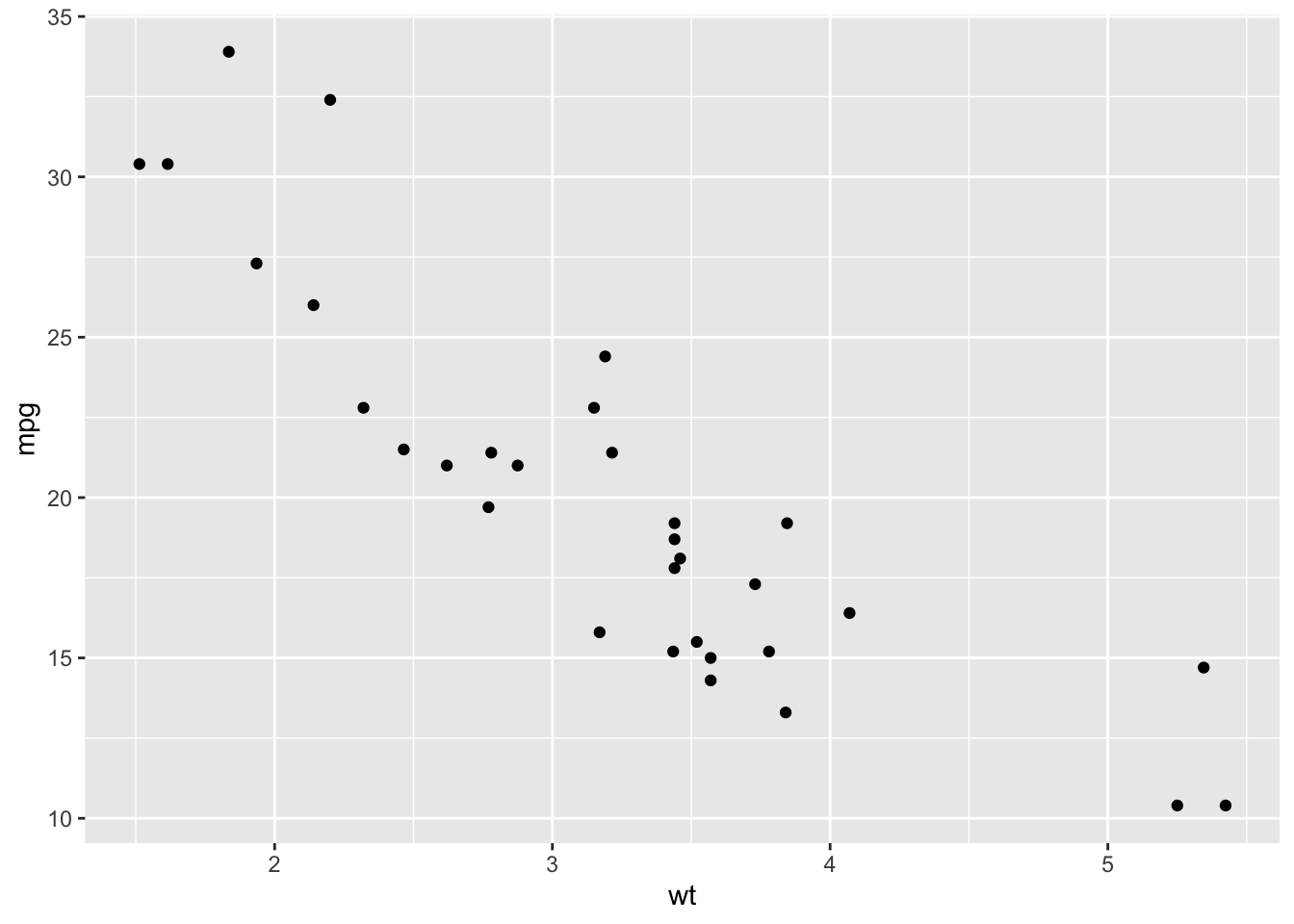
Does the horsepower and weight of a car contribute significantly to the miles per gallon of the car?
What is the relationship between horsepower and weight, with miles per gallon of the car?-
\[
H_0: \beta_1 = \beta_2 = 0
\]
\[
H_1: \beta_1 \not= \beta_2 \not= 0
\]
Code
car_model<-lm(mpg~hp+wt, data =mtcars_df)# get the F statistic and p-valuesummary(car_model)
Call:
lm(formula = mpg ~ hp + wt, data = mtcars_df)
Residuals:
Min 1Q Median 3Q Max
-3.941 -1.600 -0.182 1.050 5.854
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.22727 1.59879 23.285 < 2e-16 ***
hp -0.03177 0.00903 -3.519 0.00145 **
wt -3.87783 0.63273 -6.129 1.12e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.593 on 29 degrees of freedom
Multiple R-squared: 0.8268, Adjusted R-squared: 0.8148
F-statistic: 69.21 on 2 and 29 DF, p-value: 9.109e-12
Code
# creating a table of the modelcar_model%>%tidy()%>%gt()
term
estimate
std.error
statistic
p.value
(Intercept)
37.22727012
1.59878754
23.284689
2.565459e-20
hp
-0.03177295
0.00902971
-3.518712
1.451229e-03
wt
-3.87783074
0.63273349
-6.128695
1.119647e-06
The first step in interpreting the multiple regression analysis is to examine the F-statistic and the associated p-value, at the bottom of model summary.
In our example, it can be seen that p-value of the F-statistic is < 9.109e-12, which is less than 0.05. This means that we can reject the null and accept that either horsepower and/or weight of a car predict the miles per gallon.
To see which predictor variables are significant, we can examine the coefficients table, which shows the estimate and the associated t-statistic p-values:
Full model: mpg = 37.23 + (-0.03)\(\times\)horsepower + (-3.88)\(\times\)weight
For a given predictor, the t-statistic value evaluates whether or not there is significant association between the predictor and the outcome variable, that is whether the beta coefficient of the predictor is significantly different from zero.
It can be seen that horsepower and weight are significantly associated to changes in mpg.
Code
# The confidence interval of the modelconfint(car_model)
\(H_0\): The full model and the nested model fit the data equally well. Thus, you should use the nested model.
\(H_1\): The full model fits the data significantly better than the nested model. Thus, you should use the full model.
A likelihood ratio test compares the goodness of fit of two nested regression models.
A nested model is simply one that contains a subset of the predictor variables in the overall regression model.
We could then carry out another likelihood ratio test to determine if a model with only one predictor variable is significantly different from a model with the two predictors:
#fit full modelmodel_full<-lm(mpg~hp+wt, data =mtcars)#fit reduced modelmodel_reduced<-lm(mpg~hp, data =mtcars)#perform likelihood ratio test for differences in modelslrtest(model_full, model_reduced)
Likelihood ratio test
Model 1: mpg ~ hp + wt
Model 2: mpg ~ hp
#Df LogLik Df Chisq Pr(>Chisq)
1 4 -74.326
2 3 -87.619 -1 26.586 2.52e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#fit reduced modelmodel_reduced<-lm(mpg~wt, data =mtcars)#perform likelihood ratio test for differences in modelslrtest(model_full, model_reduced)
Likelihood ratio test
Model 1: mpg ~ hp + wt
Model 2: mpg ~ wt
#Df LogLik Df Chisq Pr(>Chisq)
1 4 -74.326
2 3 -80.015 -1 11.377 0.0007436 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Our p-values are less than 0.05 for both Chi-squared values, suggesting that the full model offers significant improvement in fit over the model with just one of the predictors.
20.1.6 Model Accuracy
In multiple linear regression, the \(R^2\) represents the correlation coefficient between the observed values of the outcome variable (y) and the fitted (i.e., predicted) values of y. For this reason, the value of R will always be positive and will range from zero to one.
An \(R^2\) value close to 1 indicates that the model explains a large portion of the variance in the outcome variable.
For multiple linear regression, there are multiple independent variables affecting the outcome. This outcome must be continuous, however, the independent variables can be numeric or categorical.
There is an inverse or negative relationship between our predictors and outcome variable. The mpg decreases with heavier weight. Higher horsepower also reduces miles per gallon performance (higher fuel consumption).